
@article{hayes2019remind,
title={REMIND Your Neural Network to Prevent Catastrophic Forgetting},
author={Hayes, Tyler L and Kafle, Kushal and Shrestha, Robik and Acharya, Manoj and Kanan, Christopher},
journal={arXiv preprint arXiv:1910.02509},
year={2019}
}
@inproceedings{kafle2020answering,
title={Answering Questions about Data Visualizations using Efficient Bimodal Fusion},
author={Kafle, Kushal and Shrestha, Robik and Cohen, Scott and Price, Brian and Kanan, Christopher},
booktitle={The IEEE Winter Conference on Applications of Computer Vision},
pages={1498--1507},
year={2020}
}
@article{kafle2019challenges,
title={Challenges and Prospects in Vision and Language Research},
author={Kafle, Kushal and Shrestha, Robik and Kanan, Christopher},
journal={arXiv preprint arXiv:1904.09317},
year={2019}
}
@inproceedings{shrestha2019ramen,
title={Answer Them All! Toward Universal Visual Question Answering Models},
author={Shrestha, Robik and Kafle, Kushal and Kanan, Christopher},
booktitle={CVPR},
year={2019}
}

@inproceedings{acharya2019tallyqa,
title={TallyQA: Answering Complex Counting Questions},
author={Acharya, Manoj and Kafle, Kushal and Kanan, Christopher},
booktitle={AAAI},
year={2019}
}
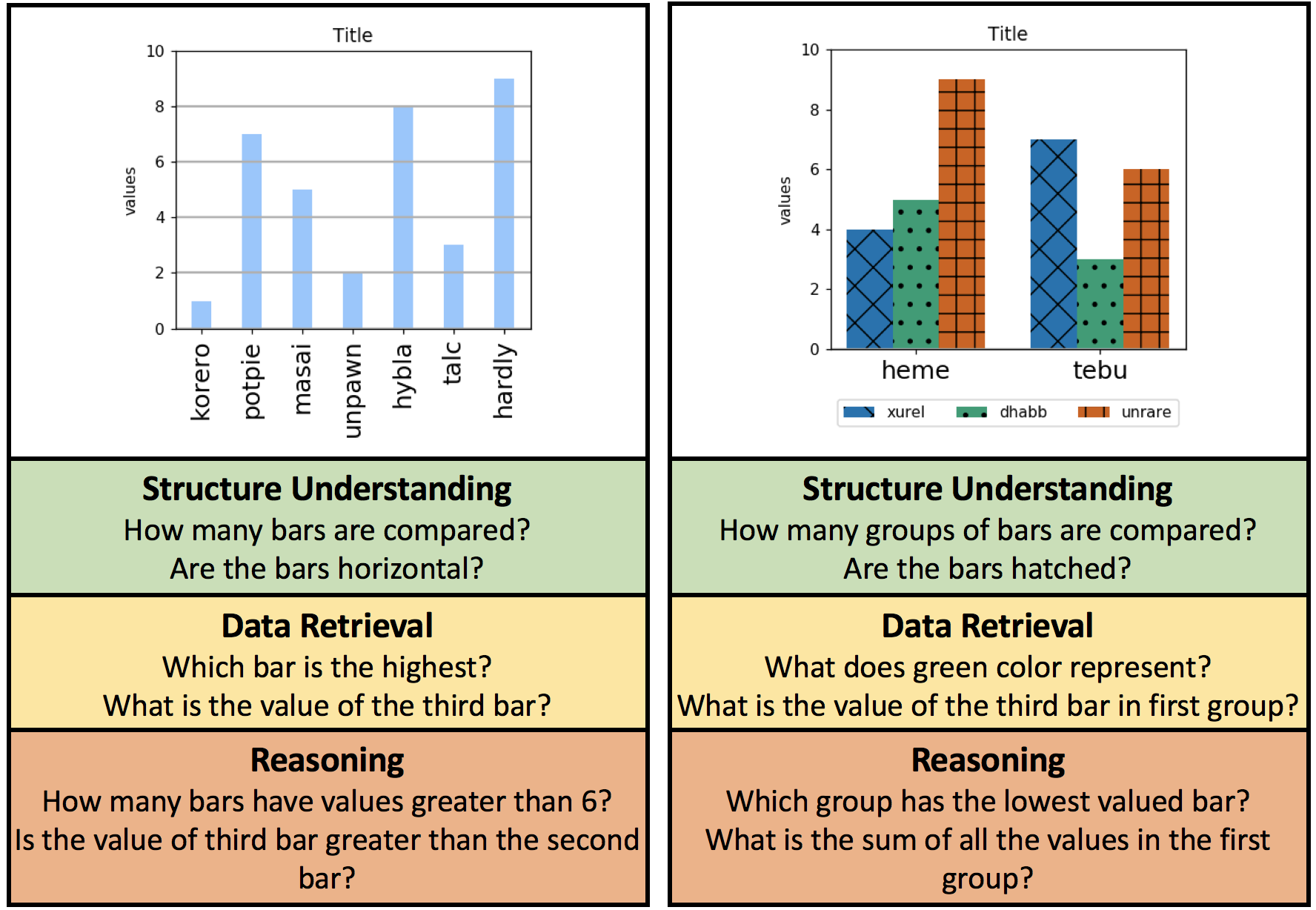
@inproceedings{kafle2018dvqa,
title={DVQA: Understanding Data Visualizations via Question Answering},
author={Kafle, Kushal and Price, Brian and Cohen, Scott and Kanan, Christopher},
booktitle={CVPR},
year={2018}
}

@inproceedings{kafle2017analysis,
title={An Analysis of Visual Question Answering Algorithms},
author={Kafle, Kushal and Kanan, Christopher},
booktitle={ICCV},
year={2017}
}
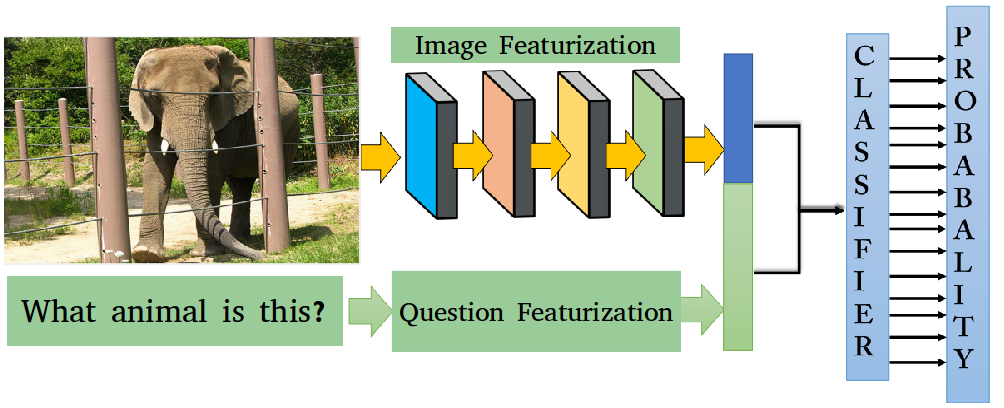
@inproceedings{kafle2017data,
title={Data Augmentation for Visual Question Answering},
author={Kafle, Kushal and Yousefhussien, Mohammed and Kanan, Christopher}
booktitle={INLG},
year={2017}
}
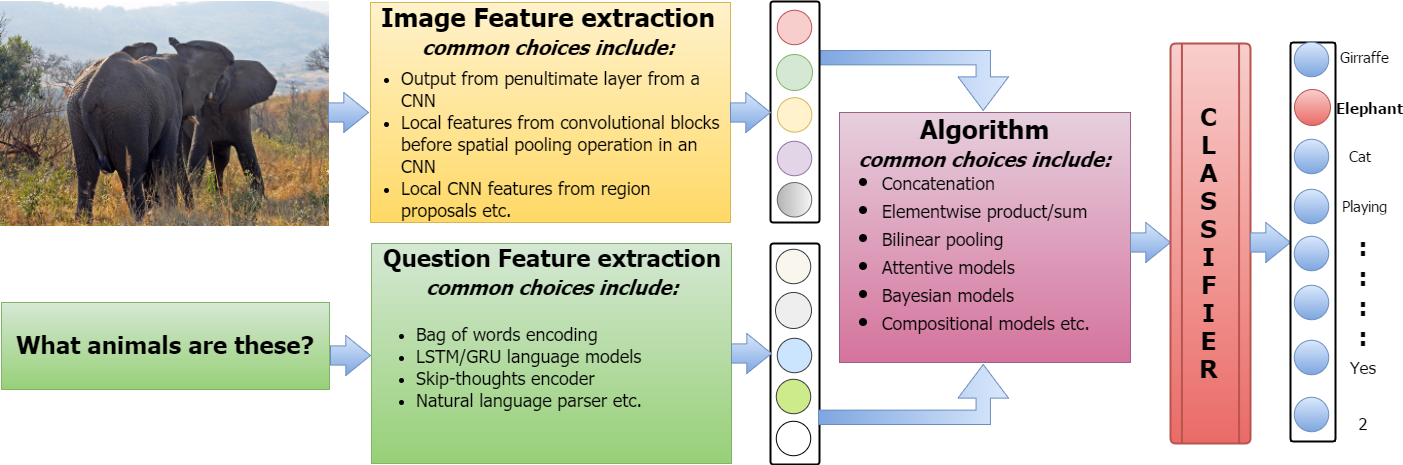
@article{kafle2017visual,
title={Visual question answering: Datasets, algorithms, and future challenges},
author={Kafle, Kushal and Kanan, Christopher},
journal={Computer Vision and Image Understanding},
year={2017}
}
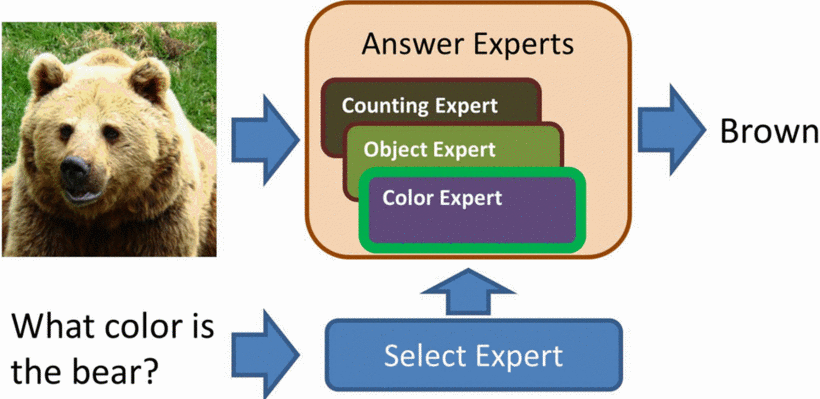
@inproceedings{kafle2016answer,
title={Answer-type prediction for visual question answering},
author={Kafle, Kushal and Kanan, Christopher},
booktitle={CVPR},
year={2016}
}